Moderne Softwareentwicklung benötigt klare, reproduzierbare und teamtaugliche Prozesse. Gerade kleine und mittlere Teams profitieren von einem Workflow, der Stabilität gewährleistet, ohne unnötige Komplexität einzuführen.
Der folgende Git‑Workflow hat sich in realen Projekten bewährt und ist darauf ausgelegt, Qualität, Transparenz und Deployment‑Sicherheit sicherzustellen.
Kein Overhead, keine unnötigen Sonderregeln, aber klare Leitlinien für ein professionelles Arbeiten.
Zielsetzung #
Der Workflow verfolgt das Ziel, einen stabilen, nachvollziehbaren und automatisierbaren Entwicklungsprozess zu etablieren.
Er sorgt dafür, dass:
- Codequalität gesichert ist, weil Reviews, Tests und CI‑Checks verpflichtend sind.
- Deployments reproduzierbar bleiben, da jeder Schritt dokumentiert und automatisiert ist.
- Feature‑Entwicklung und Release‑Management getrennt voneinander stattfinden, was Risiken reduziert.
- Teams effizient arbeiten, weil der Prozess klar strukturiert ist und keine unnötigen Entscheidungen erfordert.
Damit eignet sich der Workflow besonders für Teams, die Wert auf Stabilität legen, aber nicht in komplexe Git‑Flow‑Varianten abgleiten möchten.
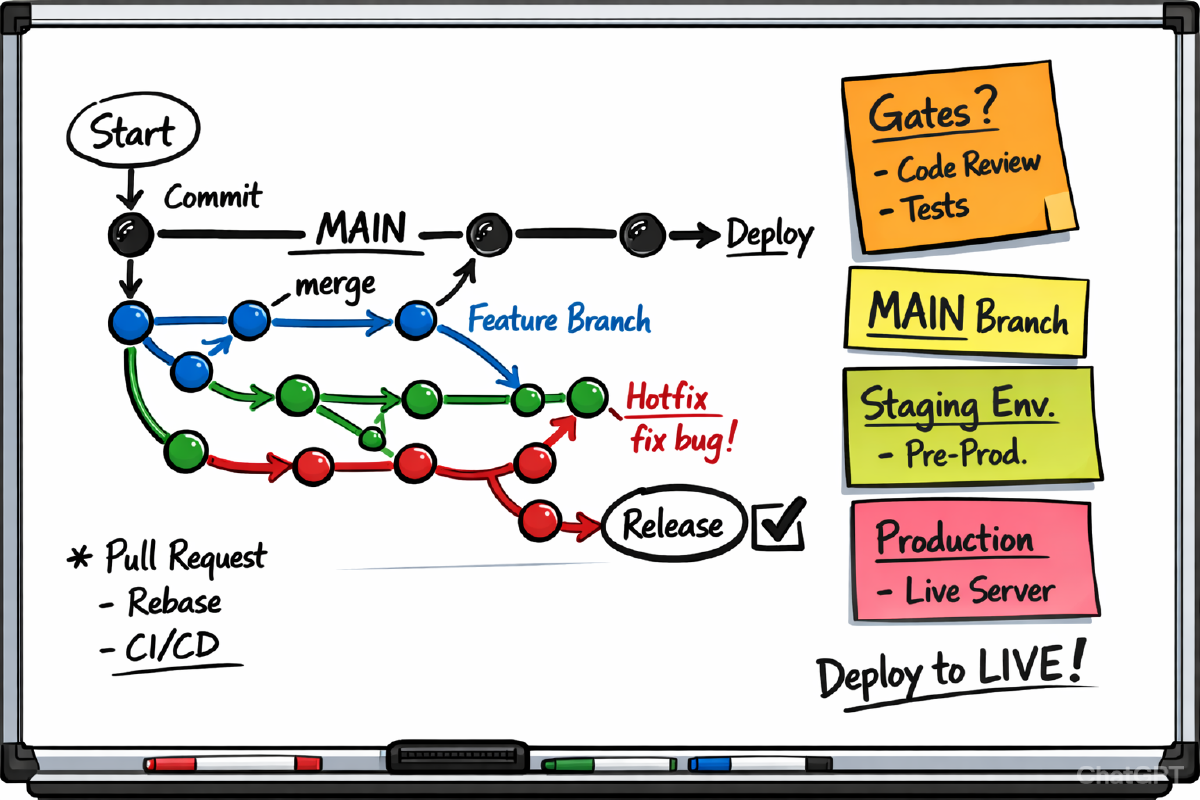
Permanente Branch‑Struktur #
Der Prozess basiert auf drei dauerhaften Branches, die klar definierte Rollen haben:
- main – stabiler Integrationsbranch für getesteten, reviewten Code. Er repräsentiert den aktuellen Entwicklungsstand, der jederzeit deploybar ist.
- staging – dient als QA‑, UAT‑ und Integrationsumgebung. Hier wird geprüft, ob der Code nicht nur technisch, sondern auch fachlich korrekt funktioniert.
- production – enthält ausschließlich den Code, der live im Produktivsystem läuft.
Diese Struktur vermeidet unnötige Branch‑Hierarchien: Entwicklung auf main, Validierung auf staging, Live-Betrieb auf production.
Branch Policies #
Auf allen permanenten Branches gelten verbindliche Richtlinien, die die Qualität und Nachvollziehbarkeit sichern:
- Pull Requests sind verpflichtend – kein Code gelangt ohne Review in einen permanenten Branch.
- Direkte Pushes sind verboten – verhindert unkontrollierte Änderungen und schützt die Stabilität.
- Mindestens ein Reviewer – fördert Wissenstransfer und reduziert Fehler.
- Erfolgreiche Build‑Pipeline – verhindert, dass fehlerhafter Code integriert wird.
- Verlinkung eines Work Items – stellt sicher, dass jede Änderung einen fachlichen oder technischen Kontext hat.
- Conventional Commits1 – sorgen für konsistente Commit‑Nachrichten und erleichtern Release Notes, Changelogs und Automatisierung.
Diese Kombination aus Policies mag auf den ersten Blick streng erscheinen, doch genau das schafft die Grundlage für professionelles Arbeiten. Sie verhindert nicht nur technische Fehler, sondern etabliert eine Kultur der gemeinsamen Verantwortung: Code wird nicht mehr isoliert geschrieben, sondern im Team validiert. Die Verknüpfung mit Work Items stellt sicher, dass keine “Geisteränderungen” entstehen, deren Zweck später niemand mehr nachvollziehen kann. Und Conventional Commits machen aus der Versionshistorie ein maschinenlesbares Protokoll, das automatisierte Prozesse erst möglich macht.
Feature‑Branches #
Die eigentliche Entwicklung findet ausschließlich auf kurzlebigen (wenige Tage) Branches statt:
feature/*– neue Featuresfix/*– kleinere Fehlerbehebungenhotfix/*– dringende Korrekturen für staging oder production
Die Basis ist immer main, um sicherzustellen, dass neue Arbeit auf dem aktuellen Stand beginnt.
In der Praxis bedeutet das: Ein Feature-Branch wird erstellt, sobald die Arbeit an einem Work Item beginnt, und gelöscht, sobald der Code in main gemerged wurde. Die Benennung folgt einem klaren Muster: feature/WORKITEM-123-kurze-beschreibung macht auf einen Blick deutlich, worum es geht. Feature-Branches sollten klein bleiben: maximal 3-5 Tage, besser kürzer. Das minimiert Merge-Konflikte und hält Reviews handhabbar. Ein Branch, der wochenlang existiert, ist ein Warnsignal: Entweder ist das Work Item zu groß geschnitten, oder es fehlt an Priorisierung.
Kurzlebige Branches reduzieren nicht nur technische Risiken, sondern fördern auch einen kontinuierlichen Entwicklungsrhythmus. Wer täglich kleine, abgeschlossene Änderungen integriert, vermeidet die gefürchteten “Mega-Merges” am Ende eines Sprints.
Merge‑Request‑Flow #
Der Merge-Prozess ist das Herzstück des Workflows. Er verbindet menschliche Kontrolle mit automatisierter Qualitätssicherung und stellt sicher, dass main jederzeit stabil bleibt.
Der Ablauf ist schlank:
- Feature‑Branch von main erstellen
- Entwicklung und Push → CI führt Build und Tests aus
- Pull Request in Richtung main
- Pipeline muss erfolgreich sein
- Code Review
- Merge in main
Dieser Flow mag simpel erscheinen, doch seine Stärke liegt in der Konsequenz: Kein Schritt kann übersprungen werden. Die CI-Pipeline fungiert als erster Filter – schlägt der Build fehl oder brechen Tests, wird der Pull Request nicht einmal zur Review freigegeben. Das spart den Reviewern Zeit und verhindert, dass offensichtlich fehlerhafter Code diskutiert werden muss.
Das Code Review selbst ist nicht nur eine technische Kontrolle, sondern auch ein Moment des Wissenstransfers. Reviewer lernen neue Codebereiche kennen, Entwickler erhalten Feedback zu ihrem Ansatz, und das Team entwickelt ein gemeinsames Verständnis von Qualität. Nach dem Merge ist der Feature-Branch obsolet und wird gelöscht – main bleibt damit übersichtlich und frei von Altlasten.
Staging‑Phase #
Nach dem Merge in main erfolgt automatisch ein Merge oder Deployment nach staging. Diese Umgebung dient als realitätsnahe Testfläche und bildet den letzten Schritt vor der Produktion.
Was genau in staging validiert wird, hängt von den Ressourcen und Anforderungen des Teams ab. In formalen Enterprise-Umgebungen können das umfangreiche QA-Prozesse sein, in kleineren Teams reicht oft manuelles Testing durch Entwickler oder Stakeholder. Entscheidend ist: Staging ist der Ort, an dem Code unter produktionsnahen Bedingungen geprüft wird, bevor er live geht.
Mögliche Validierungsschritte in staging können sein:
- QA‑Tests – technische Validierung durch dediziertes QA-Team
- Manuelles Testing – Entwickler oder Product Owner testen selbst
- UAT – fachliche Abnahme durch Stakeholder
- Integrationstests – Zusammenspiel verschiedener Komponenten
- Smoke Tests – grundlegende Funktionstests nach Deployment
- Abnahmen – finale Freigaben für das Release (falls erforderlich)
Staging ist mehr als nur eine Testumgebung – es ist der Ort, an dem Code zum ersten Mal unter realistischen Bedingungen beweisen muss, dass er funktioniert. Anders als lokale Entwicklungsumgebungen oder isolierte CI-Systeme bildet Staging die Produktionsinfrastruktur so genau wie möglich nach: gleiche Datenbanken (anonymisiert), gleiche Services, gleiche Netzwerk-Konfigurationen. Fehler, die hier auftreten, wären in der Produktion katastrophal – hier sind sie lehrreich und korrigierbar.
Die Staging-Phase fungiert damit als Sicherheitsnetz, das verhindert, dass ungetesteter oder unvollständig geprüfter Code in die Produktion gelangt. Sie gibt dem Team die Gewissheit, dass das, was released wird, tatsächlich funktioniert.
Freigabeprozess: staging → production #
Der Übergang in die Produktion ist der kritischste Moment im gesamten Workflow. Hier entscheidet sich, ob Wochen oder Monate Entwicklungsarbeit reibungslos live gehen – oder ob ein Release zurückgerollt werden muss, weil etwas übersehen wurde.
Deshalb ist dieser Prozess bewusst streng geregelt. Ziel ist ein kontrollierter, nachvollziehbarer und weitestgehend automatisierter Release‑Prozess, der Risiken minimiert und Transparenz schafft. Jeder Schritt ist dokumentiert, jede Freigabe ist nachvollziehbar, und kein Deployment erfolgt ohne explizite Bestätigung.
Freigabevoraussetzungen (Release Gates) #
Bevor Code in die Produktion gelangen kann, müssen zentrale Gates erfüllt sein. Diese Gates sind keine bürokratischen Hürden, sondern Schutzmaßnahmen, die verhindern, dass unfertige, fehlerhafte oder riskante Änderungen live gehen.
Die folgenden Gates sind Beispiele für einen formalen Release-Prozess. Nicht jedes Team benötigt alle vier Gates in dieser Ausprägung. Ein kleineres Team ohne dedizierte QA-Abteilung kann die QA-Freigabe durch “erfolgreiche manuelle Tests durch Entwickler” ersetzen. Ein Startup ohne Product Owner kann UAT durch “fachliche Prüfung im Team” ersetzen.
Entscheidend ist das Prinzip: Bevor Code in production geht, muss er nachweislich funktionieren – technisch und fachlich. Wie formalisiert dieser Nachweis erfolgt, richtet sich nach den Anforderungen des Projekts.
1. QA‑Freigabe (Beispiel für formalen Prozess) #
- alle Testfälle im Release‑Scope erfolgreich
- keine offenen Bugs mit Severity2 1 oder 2
- abgeschlossene Regressionstests
Alternative für kleinere Teams: Erfolgreiche manuelle Tests durch Entwickler, dokumentiert als Checklist oder im PR-Kommentar.
Die QA‑Freigabe stellt sicher, dass der Code technisch stabil ist und keine bekannten kritischen Fehler enthält.
2. UAT‑Freigabe (Beispiel für formalen Prozess) #
- fachliche Abnahme aller relevanten Work Items
- dokumentierte Zustimmung des Product Owners
Alternative für kleinere Teams: Kurzes Testing durch einen fachlichen Stakeholder oder Tech Lead, Freigabe per Slack/E-Mail.
Damit wird bestätigt, dass der Code fachlich korrekt ist und den Anforderungen entspricht. Technisch perfekter Code ist wertlos, wenn er nicht das tut, was die Nutzer brauchen.
3. Technische Checks (sollten immer automatisiert sein) #
- erfolgreiche End‑to‑End‑Tests
- Security‑Scans ohne kritische Findings
- erfolgreiche Build‑Pipeline
- keine Merge‑Konflikte zwischen staging und production
Diese Checks sollten in jedem Setup vorhanden sein, da sie automatisiert ablaufen.
Diese Checks verhindern technische Risiken und stellen sicher, dass der Code sicher und kompatibel ist.
4. Manuelle Freigabe (immer erforderlich) #
- ein definierter Verantwortlicher (z. B. Product Owner oder Tech Lead) bestätigt das Release im Environment „production"
- ohne diese Freigabe erfolgt kein Deployment
Auch in kleinen Teams sollte jemand final „OK" sagen – verhindert versehentliche Deployments.
Dieser letzte Schritt ist bewusst manuell gehalten. Auch wenn alle automatisierten Checks bestanden sind, braucht es einen Menschen, der die Gesamtsituation bewertet: Ist jetzt der richtige Zeitpunkt für ein Release? Gibt es externe Faktoren, die dagegen sprechen? Diese finale Kontrolle sorgt für maximale Verantwortlichkeit und verhindert ungewollte Deployments.
Skalierbarkeit der Gates #
Die beschriebenen Release Gates lassen sich an die Größe und Reife des Teams anpassen:
| Team-Größe | QA-Freigabe | UAT-Freigabe | Technische Checks | Manuelle Freigabe |
|---|---|---|---|---|
| Klein (3-5) | Entwickler testen selbst | Tech Lead prüft fachlich | Automatisiert (Pflicht) | Tech Lead |
| Mittel (6-15) | Rotierende QA-Rolle oder dedizierte QA-Person | Product Owner | Automatisiert (Pflicht) | Product Owner |
| Groß/Enterprise | Dediziertes QA-Team mit formalen Testplänen | Formale UAT mit Dokumentation | Automatisiert + Security/Compliance | Release Manager |
Das Prinzip bleibt gleich: Nichts geht in production, ohne dass es geprüft wurde. Die Formalität der Prüfung skaliert mit den Anforderungen.
Ablauf: staging → production #
- main → staging erfolgt automatisch nach jedem Merge
- QA und UAT prüfen den Stand in staging
- nach erfüllten Gates wird automatisch ein PR von staging → production vorgeschlagen
- Reviewer prüfen den PR technisch und fachlich
- nach Freigabe:
- Build
- Deployment nach production
- automatisches Tagging (
vX.Y.Z) - automatische Release Notes (kurz + lang)
- Veröffentlichung der Artefakte
Dieser Ablauf verbindet Automatisierung mit klaren manuellen Kontrollpunkten. Das Beste aus beiden Welten: Geschwindigkeit durch Automation, Sicherheit durch menschliche Urteilskraft.
Hotfix‑Prozess #
Fehler in der Produktion sind unvermeidlich. Entscheidend ist, wie schnell und kontrolliert sie behoben werden können. Der Hotfix-Prozess ist bewusst so gestaltet, dass er Geschwindigkeit ermöglicht, ohne die Stabilität des Workflows zu gefährden.
Bei Fehlern in staging oder production:
hotfix/*‑Branch von main erstellen- Fehler beheben
- Pull Request → main
- normaler Flow: main → staging → production
Hotfixes werden niemals direkt in staging oder production durchgeführt. Das mag auf den ersten Blick umständlich erscheinen – warum nicht einfach schnell den Fehler in production fixen? – doch dieser Weg führt unweigerlich zu Inkonsistenzen. Ein direkter Fix in production würde bedeuten, dass main und staging plötzlich einen anderen Stand haben. Spätere Merges würden den Fix überschreiben oder zu schwer durchschaubaren Konflikten führen.
Der beschriebene Prozess stellt sicher, dass alle Umgebungen synchron bleiben und der Hotfix vollständig getestet wird, bevor er live geht. In der Praxis bedeutet das: Selbst dringende Fixes durchlaufen CI, Review und staging – nur eben priorisiert und beschleunigt.
Release‑Tags #
Nach erfolgreichem Merge in production wird automatisch ein Tag gesetzt:
- Format:
vX.Y.Z
Der Tag markiert exakt den Commit, der live ist. Dies ist mehr als nur eine Formalität: Tags sind unveränderliche Markierungen in der Git-Historie, die jederzeit reproduzierbar machen, welcher Code zu welchem Zeitpunkt in der Produktion lief. Bei Incidents ermöglicht das schnelles Debugging (“Welcher Code war am 15. März live?”), bei Audits liefert es lückenlose Nachvollziehbarkeit, und bei Rollbacks gibt es ein klares Ziel, zu dem zurückgekehrt werden kann.
Diese Tags folgen der Semantic Versioning Convention (SemVer), die es ermöglicht, auf einen Blick zu erkennen, ob ein Release Breaking Changes, neue Features oder nur Bugfixes enthält.
Release‑Automation #
Der gesetzte Tag ist nicht das Ende des Prozesses, sondern der Auslöser für die finale Automatisierung. Eine Release‑Pipeline wird gestartet, die alle notwendigen Artefakte erzeugt und dokumentiert:
- Artefakte erzeugt (Binaries, Container-Images, Packages)
- automatische Release Notes generiert
- Dokumentation aktualisiert
- Benachrichtigungen versendet
Damit wird jeder Release vollständig dokumentiert und automatisiert ausgeliefert. Was früher manuell zusammengestellt werden musste – Release Notes schreiben, Stakeholder informieren, Artefakte hochladen – geschieht jetzt in Sekunden. Das spart nicht nur Zeit, sondern eliminiert auch menschliche Fehler: keine vergessenen Benachrichtigungen, keine fehlenden Artefakte, keine inkonsistenten Release Notes.
Automatische Release Notes (optional KI‑gestützt) #
Die Pipeline sammelt:
- Work Items
- Pull Requests
- Commits
und erzeugt daraus:
- eine Kurzfassung für Endnutzer (Was ist neu? Was wurde behoben?)
- eine Langfassung für technische Stakeholder (Welche Pull Requests? Welche technischen Änderungen?)
Optional kann dieser Prozess durch KI-Modelle unterstützt werden, die aus den gesammelten Daten lesbare, kontextuelle Release Notes generieren. Das Ergebnis: Dokumentation, die tatsächlich gelesen wird, weil sie verständlich und relevant ist.
Dies reduziert manuellen Aufwand erheblich und sorgt für konsistente, vollständige Release‑Dokumentation, die nicht mehr davon abhängt, ob jemand daran denkt, sie zu schreiben.
Prozessübersicht #
feature/*
↓ (PR, CI, Review)
main
↓ (automatisch)
staging
↓ (QA, UAT, Gates erfüllt)
PR staging → production
↓ (Review, Approval)
production
↓ (Deployment erfolgreich)
Tag vX.Y.Z
↓ (automatisch)
Release-Pipeline
→ Artefakte
→ AI Release Notes (kurz + lang)
→ Dokumentation
→ NotificationsGrenzen und Anwendbarkeit #
Ich möchte an dieser Stelle nicht verschweigen, dass auch dieser Workflow nicht für jedes Team und jedes Projekt gleichermaßen geeignet ist. Er entfaltet seine Stärken vor allem in bestimmten Kontexten:
Dieser Workflow passt gut, wenn:
- das Team aus 3-20 Entwicklern besteht (klein genug für Abstimmung, groß genug, dass Prozesse nötig sind)
- Stabilität wichtiger ist als maximale Deployment-Geschwindigkeit
- regulatorische Anforderungen oder Audit-Trails erforderlich sind
- mehrere Umgebungen (dev, staging, production) existieren
- das Team bereit ist, in CI/CD-Infrastruktur zu investieren
Weniger geeignet für:
- Ein- oder Zwei-Personen-Projekte – hier ist der Overhead zu groß
- Experimentelle Prototypen oder MVPs, bei denen schnelle Iteration wichtiger ist als Stabilität
- Teams, die mehrmals täglich deployen möchten (Continuous Deployment im engeren Sinne) – der staging-Gate verlangsamt bewusst
Anpassbar für verschiedene Team-Größen:
- Kleine Teams (3-5 Entwickler) ohne dediziertes QA: Entwickler testen selbst in staging, Tech Lead gibt final frei. Die Release Gates sind vereinfacht, aber das Prinzip bleibt.
- Mittlere Teams (6-15 Entwickler): QA-Rolle kann rotieren, UAT durch Product Owner oder fachliche Stakeholder.
- Große Teams/Enterprise: Formale QA-Abteilung, dokumentierte UAT, Compliance-Anforderungen – hier entfaltet der Workflow seine volle Stärke.
Trade-offs, die bewusst eingegangen werden:
- Geschwindigkeit vs. Sicherheit: Der Weg von main über staging nach production dauert länger als ein direktes Deployment. Das ist gewollt, kostet aber Zeit.
- Flexibilität vs. Konsistenz: Keine Ausnahmen zu erlauben (keine direkten Pushes, keine Skip-Reviews) schränkt in Ausnahmesituationen ein.
- Automatisierung vs. Kontrolle: Manuelle Freigaben verhindern vollständig automatisierte Deployments. Das ist ein bewusster Kontrollpunkt, aber auch ein manueller Eingriff.
Wer täglich oder mehrmals täglich deployen möchte, braucht einen anderen Ansatz – etwa Trunk-Based Development mit Feature Flags. Wer hingegen wöchentliche oder zweiwöchentliche Releases fährt und dabei maximale Sicherheit benötigt, findet hier eine solide Grundlage.
Dieser Ansatz lässt sich modifizieren und an andere Anforderungen anpassen.
Fazit #
Dieser Git-Workflow verzichtet auf komplexe Branch-Strukturen, langlebige Feature-Branches oder manuelle Deployment-Schritte, wo Automatisierung möglich ist. Gleichzeitig lässt er an den entscheidenden Stellen – Code Review, QA-Freigabe, finales Deployment – keinen Raum für Shortcuts.
Die Stärke dieses Ansatzes liegt in seiner Klarheit. Jedes Teammitglied weiß zu jedem Zeitpunkt, wo Code steht und welche Schritte als nächstes folgen. Es gibt keine Grauzone, keine Sonderregeln für “dringende” Änderungen, keine Diskussionen darüber, ob ein Review “diesmal” ausnahmsweise übersprungen werden kann.
Für Teams, die Wert auf Stabilität, Nachvollziehbarkeit und Automatisierung legen, bietet dieser Workflow eine gute Grundlage.
Vorschaubild #
Erstellt mit ChatGPT
-
Conventional Commits ist eine Konvention für Commit-Nachrichten mit dem Format
type(scope): description. Mehr Details: conventionalcommits.org ↩︎ -
Severity klassifiziert den Schweregrad von Bugs: 1 = kritisch (Systemausfall), 2 = schwerwiegend (wichtige Features defekt), 3 = mittel, 4 = niedrig. ↩︎